Die Datenfeldbeschreibung beschreibt den feldweisen Aufbau der Datenobjekte. Sie enthält neben optionalen Befehlszeilen zu jedem Datenfeld eine Zeile mit folgendem Aufbau
Feldname tz Indextyp Abprüfungstyp tz Feldlänge
tz steht dabei für ein Trennzeichen, z.B. das Tabulatorzeichen.
Nachfolgend ist im einzelnen erläutert, was unter Feldname, Index-, Abprüfungstyp
und Feldlänge anzugeben ist.
Feldname steht für eine eindeutige Zeichenfolge, über die das Datenfeld im DORADO angesprochen wird. Ein Feldname darf beliebig lang sein, und muß aus Buchstaben und Ziffern bestehen. Das erste Zeichen muß ein Buchstabe sein. Klein- und Großbuchstaben werden gleich behandelt.
Es empfiehlt sich, bei der Wahl der Namen dafür zu sorgen, daß sie sich möglichst in den ersten Buchstaben voneinander unterscheiden, um die Abkürzungsmöglichkeiten bei der Eingabe von Namen ausnutzen zu können.
|
Der Indextyp legt fest, ob und in welcher Form ein Feld selektierbar, also suchfähig ist. Fehlt die Angabe des Indextyps in einer Standard-Datenbank, so gilt das Feld als nicht selektierbar. Bei nicht Standard-Datenbanken muß zum Indextyp immer eine Angabe gemacht werden, und sei es ein Minus-Zeichen, um zu kennzeichnen, daß das Feld nicht suchfähig ist.
Folgende Angaben sind unter Indextyp zulässig:
|
Indextyp
|
Bedeutung
|
|---|---|
|
-
|
nicht selektierbar |
|
S
|
selektierbar |
|
w
|
wortweise selektierbar |
|
W
|
dto. zusätzliche Ablage des Gesamtinhaltes |
|
C
|
Capslock- Index, d.h. alle Indexeinträge werden intern in Großbuchstaben
gewandelt. (nur in Verbindung mit Abprüfungstyp a) |
|
|
werden intern in Großbuchstaben gewandelt |
|
*
|
Bitlistenindex |
|
.
|
dto. jedes Zeichen wird einzeln in Index übernommen |
|
?
|
Existenzindex |
Bei den Indextypen S, w, W, und C ist hinter dem Indextyp noch die Angabe einer Ziffer zwischen 1 und 9 zulässig, über die die Indexsplittung bestimmt werden kann.
Im allgemeinen wird bei einem selektierbaren Feld als Indextyp S eingetragen. Wann andere Indexangaben sinnvoll sind, und wann welche Indexsplittung gewählt werden sollte, ist in Abschnitt 2. 4 erklärt.
Der Abprüfungstyp bestimmt, welche Eingaben in einem Feld gemacht werden können. Mögliche Abprüfungstypen sind:
|
Typ
|
Bedeutung
|
|---|---|
| a | beliebige ASCII-Zeichen inkl. Leerzeichen |
| A | wie a mit automatischer Wandlung in Großbuchstaben |
| t | wie a ohne Leerzeichen |
| T | wie A ohne Leerzeichen |
| ? | wie t, aber nur für Textbausteinfelder |
| b | nur Buchstaben |
| B | wie b mit automatischer Wandlung in Großbuchstaben |
| N | nur Ziffern, automatisch führende Nullen |
| Z | nur Ziffern, linksbündig |
| R | Ziffern, sowie Vor- und Dezimalzeichen |
| r | wie R, aber automatische Formatierung auf 2 Nachkommastellen |
| D | Datum in der Form tt.mm.jj bzw. tt.mm.jjjj |
| ! | für Langtextfelder |
Fehlt der Abprüfungstyp oder ist ein Leerzeichen angegeben, so dürfen beliebige Zeichen eingegeben werden.
Die Feldlänge gibt an, wie lang der Feldinhalt maximal sein darf. Bei Standard-Datenbanken darf die Angabe fehlen. Sie wird dann aus der Länge der zugehörigen Eingabefeldes in der Bildschirmmaske bestimmt. Die maximale Feldlänge ist 127.
Die Reihenfolge der Felddefinitionen bestimmt gleichzeitig die interne Abspeicherungsreihenfolge.
Dies bedeutet, daß sobald Datenobjekte zu einer Datenbank erfaßt worden sind, die Reihenfolge der Datenfelder nicht mehr verändert werden darf, da sonst die bisher erfaßten Daten nicht mehr zu der geänderten Konfiguration passen.
Sollen also nachträglich Felder in den Datenbestand aufgenommen werden, so müssen sie hinten angehängt werden.
Über eine geeignete Maskendefinition kann man jedoch erreichen, daß nachträglich angehängte Felder so angesprochen werden können, als ob sie mittendrin eingefügt worden wären (siehe Abschnitt 2.2.2)
Ein Mehrfachfeld besteht aus mehreren Eingabefeldern, die alle gleichartig sind, beispielsweise Stichworte.
Mehrfachfelder werden in der Datenfeldbeschreibung durch Replikatoren beschreiben. Replikatoren stehen jeweils in einer eigenen Zeile und besitzen die Form
. Trennzeichen Tupelgröße Trennzeichen Wiederholungsangabe
|
|
Wenn bei einem Replikator die Anzahl fehlt, so wird 1 eingesetzt. Fehlen sowohl Tupelgröße als auch Anzahl, so wird für beides 1 eingesetzt. Steht also in einer Zeile nur ein Punkt, so wird die Definition des letzten Feldes noch einmal wiederholt.
|
Eine Felddefinition kann auch mit einem Gleichheitszeichen beginnen, dem ein Feldname folgt. Dadurch wird eine weiteres Feld zu dem angegebenen Namen definiert. Die Kenndaten des Feldes, auf das über den Namen verwiesen wird, werden übernommen, es sei denn, es sind explizit andere Kenndaten angegeben.
|
Unter Indextyp darf ebenfalls ein Gleichheitszeichen, gefolgt von einem Feldnamen, stehen. Dies bedeutet, daß alle Indexeinträge dieses Feldes in denselben Index gelangen wie die Einträge des Feldes, auf welches unter Indextyp verwiesen wird.
Bei Verweisen auf einen anderen Index darf kein Abprüfungstyp angegeben werden. Dieser wird aus dem Feld, auf das verwiesen wird, übernommen.
|
Das Erfassen, Ansehen, Ändern und Löschen von Datenbankobjekten erfolgt mit Hilfe von Bildschirmmasken. Diese Masken sind ähnlich wie ein Formular aufgebaut, d.h. sie bestehen aus Feldern, die ausgefüllt werden, und ergänzendem Text, der zur Erläuterung dient und nicht verändert wird.
Analog zu Formularen, die aus mehreren Seiten bestehen können, können sich Datenmasken über mehrere, maximal 9 Bildschirmseiten erstrecken.
Zu einem Datenbestand können mehrere Masken gehören, die den Dateninhalt in unterschiedlicher Form darstellen oder auch jeweils nur Teile der Daten zeigen.
Auf diese Weise kann man dem Sachbearbeiter in der Einkaufsabteilung ebenso gezielt nur die Daten vorlegen, die für ihn wichtig sind, wie seinem Kollegen in der Finanzbuchhaltung. Masken bilden gewissermassen ein Sichtfenster auf den gespeicherten Datenbestand.
Masken werden als Textbausteine erfaßt. Der Datenbank-Generator wandelt einen solchen Textbaustein in eine Programmdatei, über die später in den verschiedenen DORADO-Programmen auf die Datenobjekte zugegriffen wird.
Der Name der Maskentextbausteine ist frei wählbar. Es ist jedoch empfehlenswert, den Namen so zu wählen, daß man durch ihn schon erkennen kann, daß es sich um eine DORADO-Maske handelt. Der Datenbank-Generator schlägt beim Erstellen einer neuen Datenbank als Namen für die Maskendatei
*DORADO+MSK+a
vor. Dabei steht a für die Datenbankanwahl.
Der Aufbau einer Datenmaske in einem Textbaustein sieht so aus, daß man das 'Bildschirmformular' einfach als Text erfaßt. Alle ergänzenden Texte werden in der Form eingetragen, wie sie später auf dem Bildschirm erscheinen sollen. Dabei können zur leichteren Gestaltung Lineale und Tabulatoren verwendet werden. Wenn Tabulatoren verwendet werden, so muß zuvor im Maskenteil ein Lineal vorhanden sein. Das Systemlineal oder ein Lineal im Datenfeldbeschreibungsteil wird nicht beachtet.
Bildschirmattribute können beliebig benutzt werden.
Eine Maske darf aus mehreren Bildschirmseiten bestehen. Je zwei Bildschirmseiten sind durch ein Formularvorschubzeichen (F7) voneinander zu trennen. Man sollte darauf achten, daß eine Seite nicht mehr Zeilen umfaßt, als der Bildschirm, auf dem hinterher die Maske benutzt werden soll, zur Verfügung stellt.
Überall dort, wo in der Maske ein Eingabefeld sein soll, muß dieses durch unterstrichene Leerzeichen markiert werden. Es müssen genauso viele unterstrichene Leerzeichen vorhanden sein, wie das Eingabefeld Stellen haben soll.
Die ersten 2 Zeilen einer jeden Bildschirmseite sollten leer sein, also nur eine Zeilenschaltung enthalten, da hier programmseitig Meldungen eingeblendet werden.
Das erste Eingabefeld auf der ersten Bildschirmseite ist das Objektnummernfeld, also das Feld, in dem die interne Nummer des Datenbankobjekts angezeigt wird. Es sollte möglichst als einziges Feld in der Zeile stehen, da auch hinter diesem Feld von der Bearbeitung Hinweistexte ausgegeben werden. Das Objektnummernfeld sollte fünfstellig sein.
Die Abarbeitungsreihenfolge ist die Abfolge in der Cursor bei der Bearbeitung des Objektes durch die einzelnen Eingabefelder positioniert wird.
Die Eingabefelder werden im DORADO standardmäßig in der Reihenfolge abgearbeitet, wie sie im Maskentextbaustein stehen, also von links oben nach rechts unten.
Sollen die Felder in einer anderen Reihenfolge abgearbeitet werden, so müssen die definierten Bildschirmfelder statt mit unterstrichenen Leerzeichen mit einer unterstrichenen Nummer beginnen. Diese Nummer gibt an, als wievieltes Feld auf dieser Bildschirmseite das Feld angesprochen werden soll.
Das Feld, welches als erstes angesprochen werden soll (das ist immer die Objektnummer), muß also mit einer unterstrichenen 1 beginnen, das nächste mit einer 2 usw. Die Reihenfolgenummern werden über das ganze Objekt hinweg gezählt. Sind also auf zwei Bildschirmseiten insgesamt mit dem Objektnummernfeld 50 Felder definiert, und soll nicht die Standardreihenfolge benutzt werden, so müssen auch die Nummern 1 bis 50 als Reihenfolgenummern auftreten. Innerhalb einer Seite muß jedes Feld numeriert werden, und die Numerierung muß lückenlos sein.
Bei der Definition der Bildschirmreihenfolge kann es vorkommen, daß einem einstelligen Eingabefeld eine 2 stellige Reihenfolgenummer in der Reihenfolge zukommt. Diese Nummer paßt dann nicht mehr in das Eingabefeld. Um dennoch eine solche Zuordnung treffen zu können, kann man die Ziffern, die nicht mehr in das Eingabefeld passen, hinter das Eingabefeld schreiben. Der eigentliche Eingabeteil des Feldes muß durch ein STP-Zeichen beendet werden.
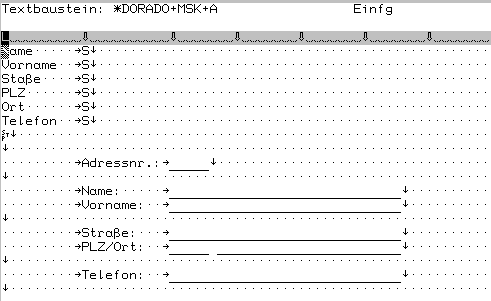
Beispiel: Es soll eine Maske für einen Anschriftenbestand definiert werden.
Neben der normalen Adresse gibt es einen zweiten Block, in dem eine abweichende
Lieferanschrift erfaßt werden soll. Beide Anschriften sollen nebeneinander
stehen. Der Cursor soll jedoch innerhalb einer Anschrift von oben nach unten
positionieren
Die Maskenbeschreibung könnte wie folgt aussehen:
Hinter der letzten Seite einer Maske darf noch eine Zusatzbeschreibung folgen. Diese wird eingeleitet durch eine Zeile, die nur ein STP-Zeichen mit einer Zeilenschaltung enthält.
Die Zusatzbeschreibung ist zeilenweise aufgebaut. Sie kann zum einen Befehlszeilen enthalten. Zum anderen kann hier eine Datenfeldzuordnung definiert werden.
Im Normalfall werden die Maskenfelder eins zu eins den Feldern des Datensatzes zugeordnet, d.h.:
| 1. Datenfeld | = 2. Maskenfeld |
| 2. Datenfeld | = 3. Maskenfeld |
Zur Erinnerung : Das 1. Maskenfeld enthält die Objektnummer, die nicht zum Datensatz gehört und somit zu keinem Datenfeld gehört.
Soll eine hiervon abweichende Zuordnung getroffen werden, so muß dies
in der Zusatzbeschreibung im Maskenbaustein erfolgen.
Dazu muß in der Bildschirmreihenfolge für jedes Feld der Maske angegeben
werden, zu welchem Datenfeld es gehört. (Das Objektnummernfeld ist hiervon
natürlich ausgenommen.) Die Datenzuordnung wird getroffen, indem für
jedes Bildschirmfeld in einer Zeile der zugehörige Feldname angegeben wird.
|
Um Schreibarbeit zu sparen, sind in der Datenfeldzuordung auch Replikatoren zulässig. Sie haben die Form
. Zahl
Ein Replikator . 12 bedeutet, daß den nächsten 12 Feldern auf dem Bildschirm (in Cursorreihenfolge) auch die nächsten 12 Felder aus der Feldbeschreibung zuzuordnen sind.
|
Sowohl in der Datenbestandsbeschreibung als auch in der Zusatzbeschreibung der Maske dürfen zusätzliche Befehle zur Festlegung verschiedener Datenbank-Parameter vorhanden sein.
Jeder Befehl steht in einer eigenen Zeile, die mit einem Stern beginnt, dem ein Befehlsname folgt. In Abhängigkeit von dem Befehl folgt dann ein Trennzeichen (z.B. ein Tabulator) und weitere Information.
Nicht jeder Befehl ist an jeder Stelle zugelassen. Insbesondere gibt es eine Trennung zwischen solchen Befehlen, die auch in der Maskendefinition, und solchen, die ausschließlich in der Datenbestandsbeschreibung zugelassen sind.
Bei Standard-Datenbanken gibt es diese Unterscheidung nicht!
Alle Befehle dieser Gruppe haben die Form
Befehlsname Trennzeichen Feldname
Diese Befehle dienen dazu, Datenfeldern weitere, insbesondere maskenspezifische Eigenschaften zuzuordnen. Befehle dieser Gruppe können mehrfach auftreten und dürfen sowohl in der Datenfeldbeschreibung (natürlich erst nach der Definition des angesprochenen Feldes), als auch in der Maskendefinition stehen.
|
Befehlsname
|
Wirkung
|
|---|---|
Mußfeld |
für das angegebene Feld besteht Eingabezwang |
Direktaufruf |
Inhalte zu diesem Feld gelten für Suchvorgänge als besonders wichtig und werden deshalb beim Erfassen bzw. beim Ändern in Zusatzindices übernommen, um sofort für Suchvorgänge zur Verfügung zu stehen. Außerdem werden diese Felder beim Direktaufruf in der Übersichtsliste der gefundenen Objekt angezeigt (soweit nichts anderes konfiguriert ist) |
Konstant |
das Feld kann über diese Maske nicht verändert werden |
Unsichtbar |
das angegebene Feld erscheint auf keiner Maske, ist aber z.B. im Verarbeitungsprogramm
bzw. in der Hintergrundverbeitung zugreifbar. Felder, die nicht in einer Maske vorhanden sind gelten automatisch als unsichtbar. |
Geschützt |
das Feld ist in dieser Datenbankmaske gar nicht zugreifbar |
.
Steht einer dieser Befehle in der Datenfeldbeschreibung, so wird dem angegebenen Feld immer, d.h. in jeder Maske, die entsprechende Eigenschaft zugeordnet. Stehen die Befehle jedoch in der Zusatzbeschreibung zu einer Maske, so haben sie auch nur für diese eine Maske Gültigkeit.
Der Befehl Geschützt ist somit in der Datenbestandsbeschreibung
unsinnig, da durch ihn das entsprechende Feld für immer geschützt
würde. Das bedeutet, daß das Feld überhaupt nicht zugreifbar
ist.
Mit Hilfe von Vorbesetzungsbefehlen kann man dafür sorgen, daß beim Erfassen von neuen Objekten einzelne Felder automatisch mit bestimmten Werten besetzt werden.
Zum einen gibt es die Möglichkeit, über den Befehl
*Vorbesetzung
einem Datenfeld eine beliebige Zeichenfolge als Vorbesetzung zuzuordnen. Eine solche Vorbesetzung darf selbstverständlich manuell überschrieben werden.
Über den Befehl
*Tagesdatum
kann man dafür sorgen, daß das aktuelle Tagesdatum als Vorbesetzung in ein Datenfeld eingesetzt wird. Abhängig von der Feldlänge erscheint das Tagesdatum entweder in der Form tt.mm.jj oder tt.mm.jjjj
|
Vorbesetzungen werden auch dann vorgenommen, wenn das Datenfeld mit dem Attribut konstant versehen ist, wenn es also manuell nicht verändert werden kann.
Kommentarzeilen sind überall dort zulässig, wo Befehlszeilen erlaubt sind, also in der Feldbeschreibung und in der Zusatzbeschreibung zu einer Maske. Eine Kommentarzeile beginnt mit zwei Sternchen und endet am Zeilenende.
Es gibt noch verschiedene weitere Befehlsgruppen, die so bedeutend sind, das ihnen nachfolgend eigene Abschnitte oder Kaiptel gewidmet sind. Dies sind:
Bei Definition eines selektierbaren Feldes durch den Indextyp S wird vom Generator in Abhängigkeit vom Abprüfungstyp festgelegt, wie die Suchinformation abgespeichert wird.
Diese automatische Festlegung reicht im Normalfall vollkommen aus !
Man kann jedoch in einzelnen Fällen durch manuelle Zusatzsteuerungen Suchvorgänge optimieren. Ferner können durch Angabe eines speziellen Indextyps modifizierte und erweiterte Suchtechniken aktiviert werden.
Einen extrem schnellen Zugriff liefern die sogenannten Bitlistenindizes, die
durch den Indextyp * angesprochen werden. Sie können bei Feldern
eingesetzt werden, in denen nur sehr wenige verschiedene Einträge gemacht
werden. Bitlisten sind z.B. empfehlenswert für alle Felder, die nur 1 Zeichen
lang sind, oder aber auch für 2-stellige numerische Felder.
Die Einschränkung, daß der Indextyp * nur für
Felder mit sehr wenigen unterschiedlichen Werten benutzt werden soll, hat ihren
Grund in der Tatsache, daß für jeden möglichen Feldinhalt eine
eigene Datei erzeugt wird. Dies führt z.B. bei einem 2-stelligen numerischen
Feld zu maximal 100 Indexdateien.
Neben dem Indextyp * gibt es noch den Indextyp ., über
den ebenfalls Bitlistenindizes beschrieben werden. Beim Indextyp .
wird jedoch der Feldinhalt als Folge von einzelnen Zeichen aufgefaßt.
Jedes einzelne Zeichen wird für sich allein als Suchinformation abgelegt.
Beim Existenzindex (Indextyp ?) wird nur gespeichert, ob in einem
Feld ein Inhalt eingetragen worden ist oder nicht. Man kann somit nur nach allen
Objekten suchen, bei denen etwas in diesem Feld steht oder nach allen Objekten,
bei denen dieses Feld leer ist. Diese Suchanfragen sind natürlich besonders
schnell.
Im allgemeinen werden Groß- und Kleinbuchstaben beim Suchen nicht gleich behandelt. D.h. wird zum Beispiel in einer Literatur-Datenbank das Stichwort "DORADO" gesucht, so werden nur alle Objekte gefunden bei denen das Stichwort in genau dieser Schreibweise erfaßt worden ist. Literaturstellen mit dem Stichwort "Dorado" wird also nicht gefunden.
Eine Möglichkeit, die Probleme, die durch Groß- und Kleinschreibung entstehen, zu lösen, besteht darin, den Abprüfungstyp so zu wählen, daß bei der Erfassung automatisch alles in Großbuchstaben gewandelt wird (z.B. Abprüfungstyp A oder B). Es kann jedoch sein, daß diese Lösung nicht geeignet ist, weil bei Ausgaben in Katalogen oder Listen nicht alles groß geschrieben sein soll.
Für solche Fälle ist der Caps-Lock-Index (Indextyp C) gedacht. Er bewirkt, daß beim Suchen Groß- und Kleinbuchstaben gleich behandelt werden. Dies erfolgt dadurch, daß bei allen internen Vorgängen Klein- in Großbuchstaben gewandelt werden. Im Datenobjekt selbst bleibt der Feldinhalt jedoch in seiner ursprünglichen Schreibweise erhalten. Dies bedeutet, daß auch bei allen Ausgaben der Feldinhalt so erscheint, wie er erfaßt worden ist.
Caps-Lock-Indizes sind nur zulässig in Verbindung mit dem Abprüfungstyp a.
Bei selektierbaren Feldern wird üblicherweise der gesamte Feldinhalt als Suchinformation abgelegt. Durch Angabe des Indextyps w kann man festlegen, daß der Feldinhalt nicht als Ganzes, sondern wortweise als Suchinformation behandelt wird. Als Wort gilt dabei jede Zeichenfolge, die mit einem Buchstaben anfängt. Ein Wort endet jeweils beim nächsten Trenn- oder Sonderzeichen.
Wortweise Indizes sind beispielsweise besonders gut geeignet in Literaturdatenbanken als Indextyp für den Titel.
Der Indextyp W wirkt wie w, jedoch wird zusätzlich der gesamte Feldinhalt als Suchbegriff in den Suchindex übernommen.
Das DORADO bietet die Möglichkeit der Volltext-Recherche, d.h. man kann nach beliebigen Texten innerhalb von Dokumenten suchen.
Folgende Voraussetzungen müssen dafür erfüllt sein:
*ExplTextKennung) berücksichtigt werden. Dokuemnte
müssen auf demselben Laufwerk wie die Objekte gespeichert sein, es sei
denn, es ist über den Befehl *ExplTextLaufwerk ein anderes
Laufwerk konfiguriert worden.
Wichtigster Punkt für die Volltextrecherche ist jedoch der entsprechende Konfigurationsbefehl: das Feld, in dem der Name des Dokuements erfaßt wird, muß in der Datenbank-Konfiguration durch den Befehl
* DokumentenRecherche Feldname
gekennzeichnet werden.
Sind ein oder mehrere Felder einer Datenbank mit dem Attribut Dokumenten-Recherche
versehen, so hat dies folgende Konsequenzen:
Bei der Integration wird nicht nur der Inhalt des Dokumentenfeldes, d.h. der Name des Dokuments in die Suchinformation übernommen, sondern es wird zusätzlich der komplette Inhalt des Dokuments ausgewertet. Dazu wird das Dokument eingelesen und in einzelne Worte zerlegt. Jedes Wort wird in die Index-Datei(en) übernommen.
Ein Wort ist in diesem Zusammenhang eine Zeichenfolge, die
Satzzeichen am Wortende werden ignoriert.
Intern werden alle Worte in Großbuchstaben abgelegt. Beim Suchen ist es egal, ob die Suchzeichenfolge groß oder klein geschrieben wird.
Folgende Punkte sind im Zusammenspiel Dokumenten-Recherche und Integration noch zu beachten:
Bei automatischer Festlegung der Indexstruktur geht der Datenbank-Generator davon aus, daß es sich um eine Datenbank handelt, die relativ wenig (d.h. weniger als 1000) Datensätze enthält, und optimiert die Indexstruktur in Hinblick auf dieses Mengengerüst.
Bei größeren Datenmengen sollte man über die Angabe eines Splittungsfaktors die Indexstruktur gezielt beeinflussen.
Der Splittungsfaktor ist eine Zahl zwischen 1 und 9. Er wird direkt hinter dem Indextyp angegeben und ist zulässig bei allen Indextypen, ausgenommen Bitlisten.
Die Splittungsangabe bewirkt, daß die Suchinformation zu einem Feld nicht nur in einer einzelnen Datei gespeichert, sondern auf mehrere Dateien verteilt wird.
Dabei entscheiden der Feldinhalt sowie der Splittungsfaktor in welcher Datei die Suchinformation abgelegt wird. Beim Splittungsfaktor 1 wird in Abhängigkeit vom ersten Zeichen die Indexdatei bestimmt. Beim Splittungsfaktor 2 sind die ersten zwei Zeichen des Feldinhaltes bestimmend.
Ist in einem Feld z.B. die Postleitzahl mit nachfolgender Ortsangabe erfaßt, so gelangt bei automatischer Indexwahl die gesamte Suchinformation zu diesem Feld in eine Indexdatei. Ist der Splittungsfaktor 1, so wird die Suchinformation in Abhängigkeit vom Feldinhalt, also in Abhängigkeit von der ersten Stelle der Postleitzahl auf unterschiedliche Indexdateien verteilt. Man wird dadurch normalerweise ca. 10 Indexdateien erhalten, nämlich eine Datei für jeden Postleitzahlbereich von 0 bis 9, sowie eventuell einige Indexdateien für das Ausland. Bei einem Splittungsfaktor 2 erhält man entsprechend mehr Indexdateien (ca. 100), dafür enthält jede einzelne Indexdatei nur die Suchinformation zu entsprechend weniger Objekten.
In vielen Fällen wird man zu einem Datenbestand auch nur eine Erfassungs- und Änderungsmaske definieren.
Für diesen Normalfall sind die Standard-Datenbanken gedacht, die ein besonders bequemes Erstellen von Datenbanken erlauben.
Will man zu einem Datenbestand nun mehrere Masken haben, so sind einige zusätzliche Dinge zu beachten. Der wesentliche Punkt ist dabei, daß die Datenbeschreibung in einer eigenen Datei mit dem festgelegten Namen
*DORADO+DB+k
stehen muß. Dabei steht k für die sogenannte Datenbankkennung, die aus ein oder zwei Zeichen, im allgemeinen Buchstaben besteht.
In der Datenbeschreibung müssen alle Felder definiert sein, und zwar in der Reihenfolge, in der sie abgespeichert werden. Ferner muß zu jedem Datenfeld die Länge angegeben werden. Die Länge kann nicht automatisch vom Generator aus der Maske ermittelt werden, da es nicht notwendigerweise ein Maske mit allen Feldern geben muß.
Die Datenbeschreibung enthält alle Informationen, die zwingend benötigt werden, um ein Datenobjekt zu beschreiben.
Zu der Datenbeschreibung können nun verschiedene Masken erstellt werden. Jede Maske wird in eigenem Textbaustein erfaßt. Es ist dabei nicht erforderlich, daß eine Maske existiert, in der alle Felder enthalten sind.
In jedem Maskenbaustein wird der jeweilige Bildschirmaufbau beschrieben. Ferner kann eine Datenzuordnung festgelegt werden, und es können einzelnen Feldern maskenspezifische Eigenschaften wie z.B. Mußfeld oder konstantes Feld zugeordnet werden.